vLLM Tops the Artificial Analysis Leaderboard

How vLLM built the leading deployments of DeepSeek V3.2, MiniMax-M2.5, and Qwen 3.5 397B.
Last week, DigitalOcean published inference benchmarks across three frontier open-weight models. On DeepSeek V3.2, the deployment achieved a best per-user output throughput of 230 TPS — more than 4x what the majority of inference providers report for the same model. On Qwen 3.5 397B release, it ranked first across all 12 providers measured by Artificial Analysis, with TTFT under 1 second on 10,000-token prompts.
The notable part: the engine underneath is open source. It's vLLM.
A common assumption in production AI is that the best inference performance requires a proprietary stack. In this case, however, a community-built inference engine running on the same NVIDIA Blackwell Ultra silicon ranked first.
The optimizations behind these results are not locked in a private fork. Op fusions for DeepSeek V3.2, a custom EAGLE3 draft model for MiniMax-M2.5, and a set of fusions tuned to Qwen 3.5's linear-attention path; every change is in vLLM main or in flight to be added.
This post is about how this deployment was built.
How vLLM made it fast
The work split across three models, each with its own bottleneck and its own fix.
- DeepSeek V3.2: aggressive kernel fusion to cut overhead at low batch sizes (also applicable to DeepSeek V4).
- MiniMax-M2.5: targeted kernel fusion paired with a custom EAGLE3 draft model — trained on open-source TorchSpec and vLLM, even though the model itself is custom. The same draft works on M2.7; the architectures are identical.
- Qwen 3.5 397B: targeted fusions for the model's attention and normalization path.
The following sections walk through each model in turn.
DeepSeek V3.2: Kernel Fusion at Low Batch Sizes
At low batch sizes, DeepSeek V3.2 was bound by GPU kernel launch overhead, not compute. Each transformer layer was issuing dozens of separate kernels — small operations like normalization, rotary embedding, and quantization that the GPU itself executed in microseconds, but each carrying a fixed launch cost that dominated total time.
The fix was op fusion across the attention path. Operations that previously launched as separate kernels — Q and KV normalization, rotary embedding for Q and KV, the indexer's layer norm and rotary embedding, FP8 quantization, and KV cache writes — collapsed into a pair of fused kernels covering everything outside attention and MoE. Per-layer kernel count dropped from ~33 toward a target of ~10.
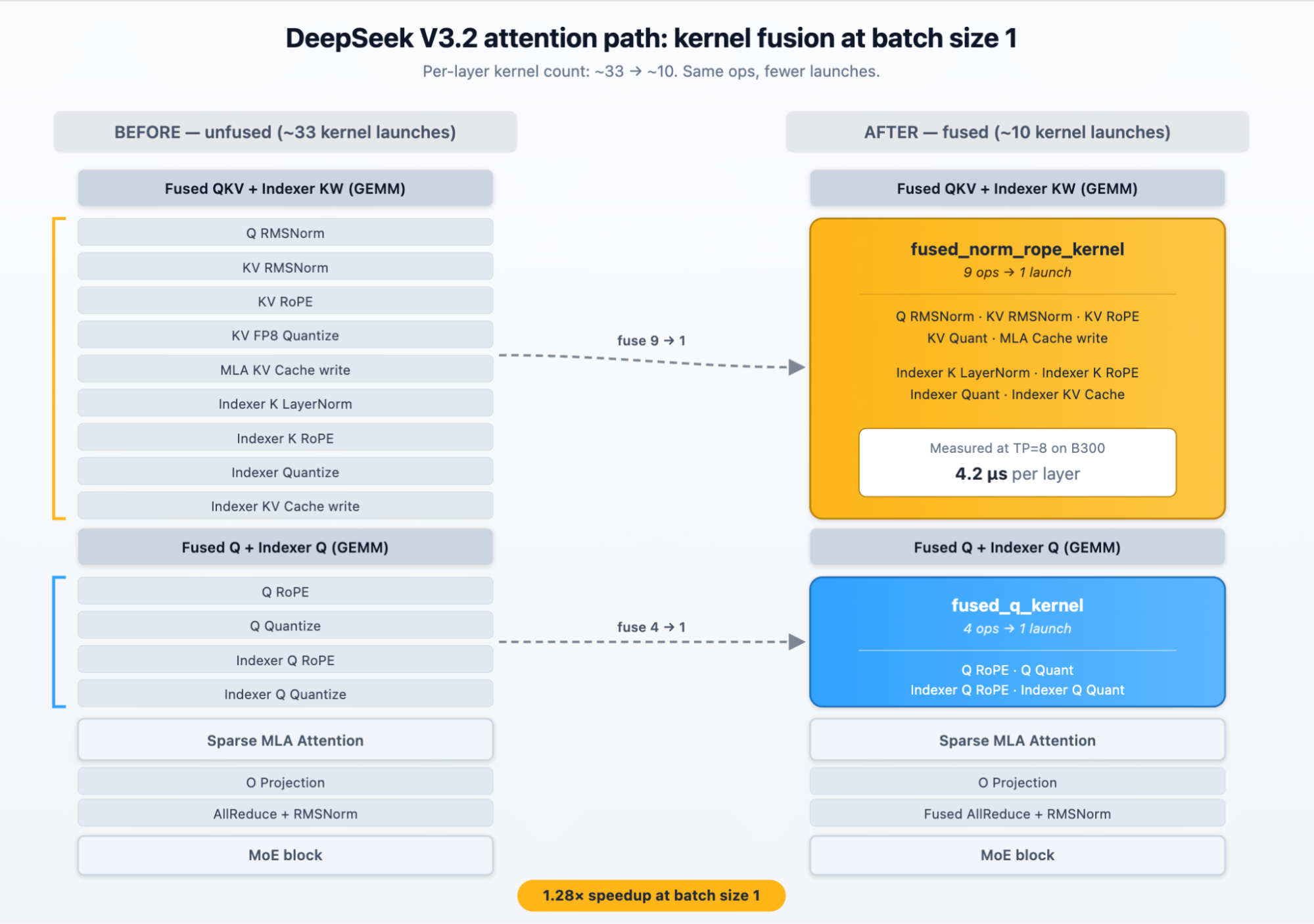
The fusion alone delivered a 1.28× speedup at batch size 1 (85.8 → 109.3 tok/s on 4× GB200, no MTP). On a single 8× B300 node at concurrency 1:
- Without MTP (TP=8): 125 tok/s
- With MTP=1 (TP=8): 234 tok/s (~90% draft acceptance rate)
- With prefill/decode disaggregation (TP=4 + TP=4 + MTP=3): 262 tok/s
Beyond fusion, two DSv3.2-specific kernels closed remaining gaps. A new router GEMM kernel — specialized for DSv3's MoE routing dimensions at small decode batch sizes — replaced the generic matmul and delivered an additional 6% speedup at batch 1 (#34302).
For the sparse attention indexer, a new TopK kernel picks the right algorithm per row based on sequence length, fitting all cases into a single CUDA graph. This contributed up to a 17% per-token latency improvement on 128K-context decode (#37421).
The same work now forms the foundation of vLLM's DeepSeek V4 support, which reuses the Q RoPE + quant and QK norm fusions from this work. The results are shown below.
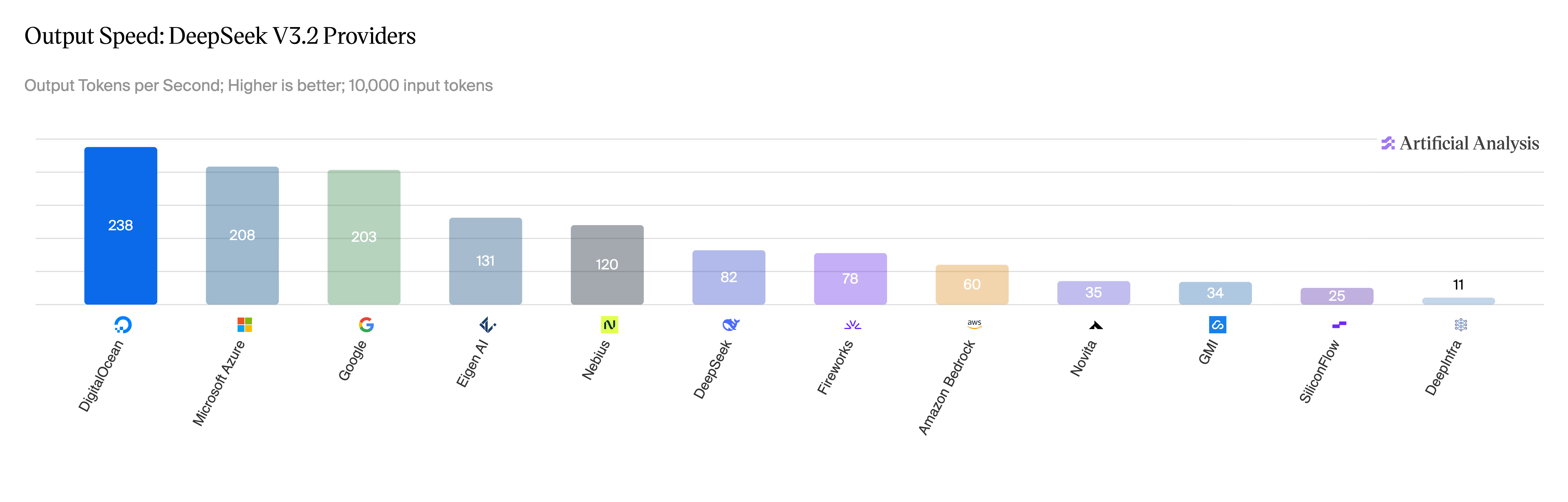
Source: Artificial Analysis, May 2026.
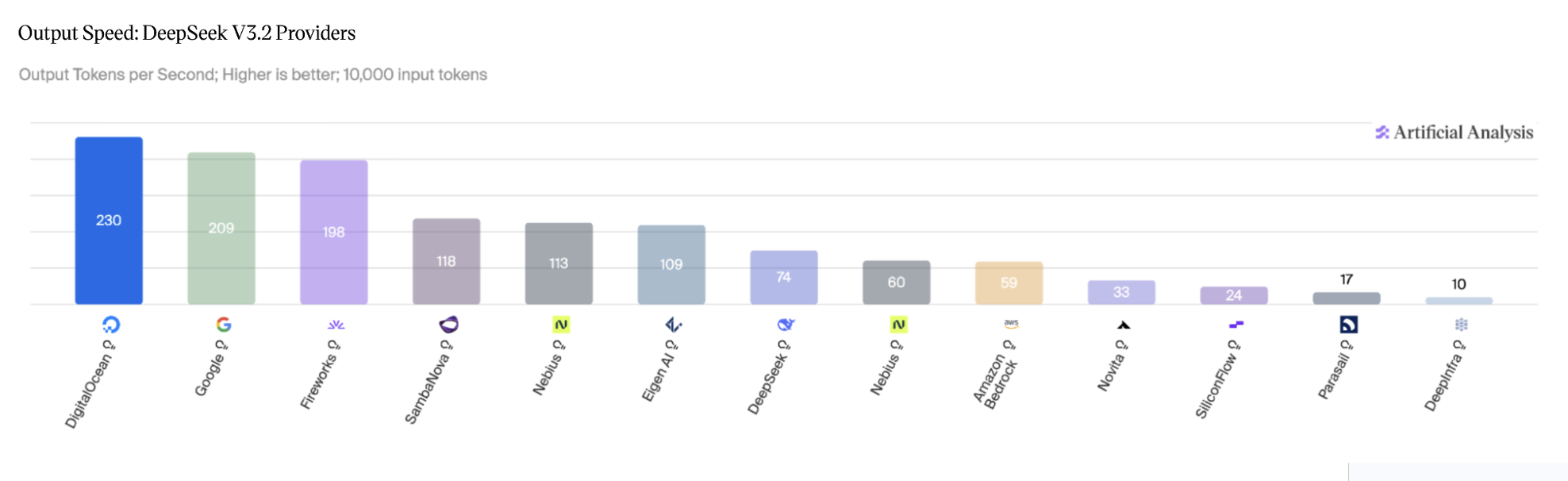
Source: Artificial Analysis, May 2026.
MiniMax-M2.5: EAGLE3 and more kernel fusion
The Inferact team trained a custom EAGLE3 draft model for MiniMax-M2.5 using TorchSpec, a torch-native online speculative decoding framework that runs FSDP draft training and vLLM-based target inference concurrently. Rather than learning from a generic supervised dataset, the draft consumes live vLLM-generated hidden states over MiniMax-M2.5-regenerated responses, training it to match the base model's exact token distribution.
Speculative decoding infrastructure improvements in vLLM's MRV2 path made this possible: a draft model metadata fix that improved acceptance rates at later draft positions (#38311) and CUDA graph support for draft prefill (#37588).
Alongside the draft model, MiniMax M2.5 received targeted kernel fusion work. A custom QK-norm fusion (fuse_minimax_qk_norm) was added to handle the model's non-standard attention normalization, in which Q and K variances are reduced across tensor-parallel ranks before the per-channel scale is applied (#37045).
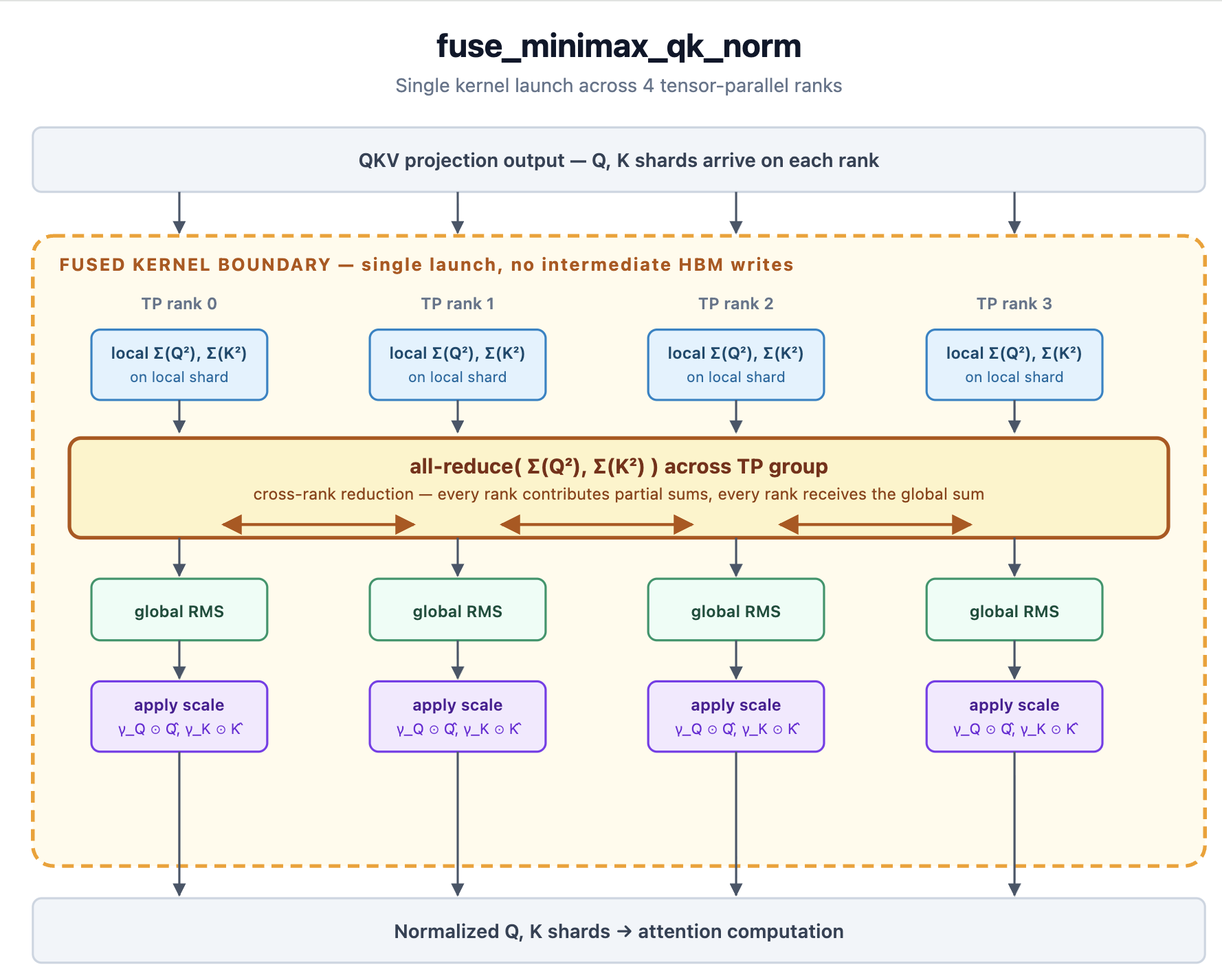
With this fusion plus the standard fuse_norm_quant, fuse_act_quant, and fuse_gemm_comms passes enabled, the ceiling experiment reached:
- 326 tok/s at concurrency 1 (TP=4, EAGLE3 + 3 speculative tokens, synthetic 100% acceptance).
This represents the upper bound for the serving stack with a perfect draft model, isolating the contribution of the fusion work from draft model quality.
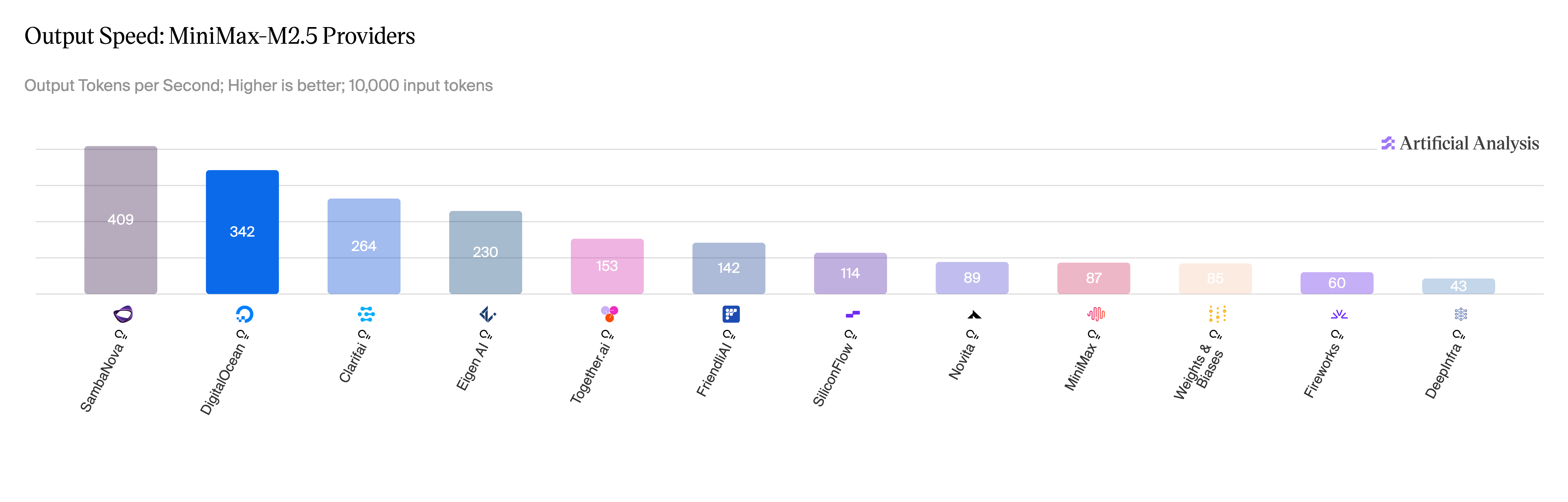
Source: Artificial Analysis, May 2026.
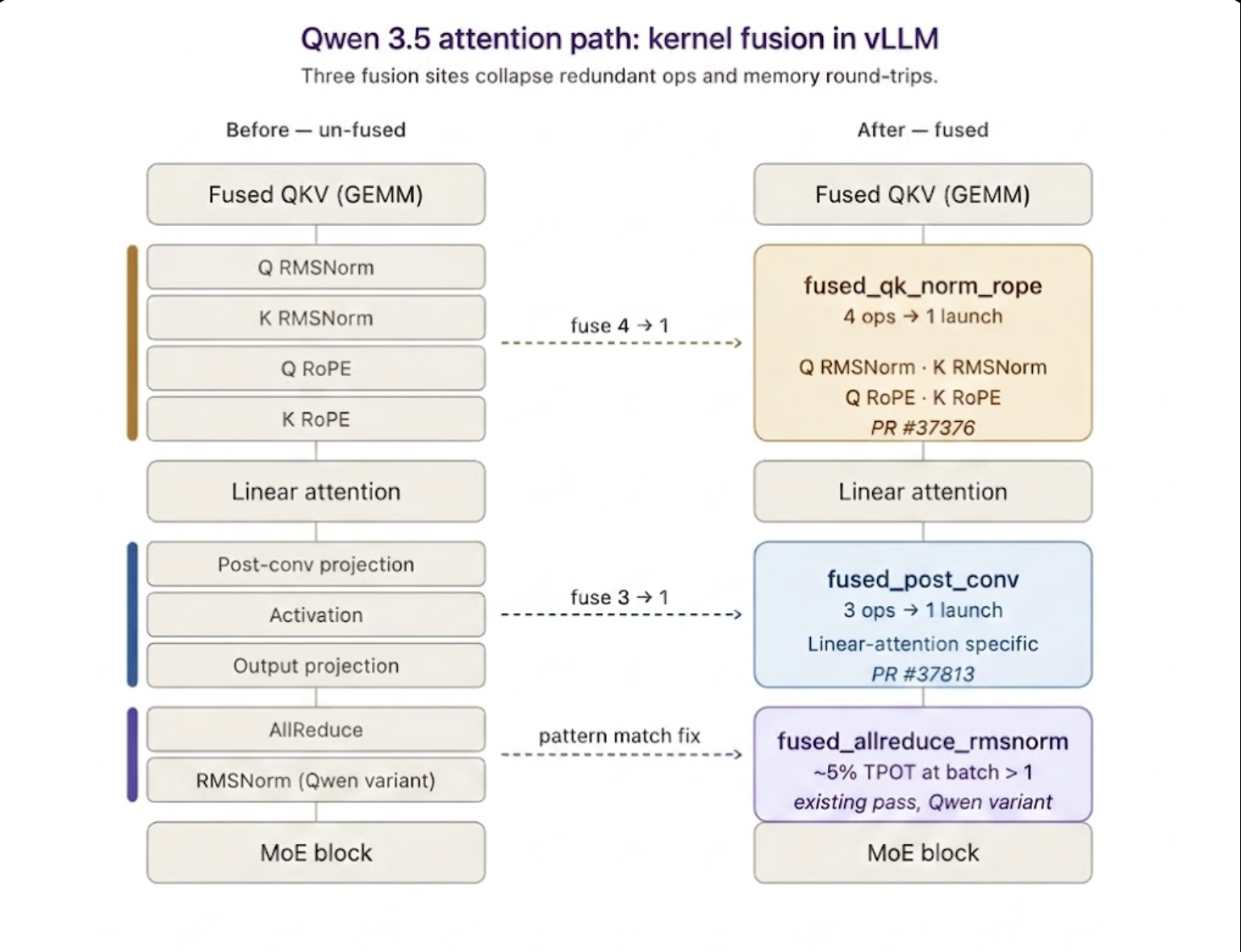
Qwen 3.5 397B: Linear attention and fusion gaps
Qwen 3.5 uses linear attention with a non-standard normalization in its attention block. Both architectural choices interact awkwardly with vLLM's standard fusion infrastructure: the post-projection convolution path is unique to linear-attention models, and the normalization variant didn't match the pattern vLLM's existing allreduce_rms fusion was looking for.
The cost showed up in the profiler. With the missed allreduce_rms fusion, roughly half of decode time was being spent on un-fused cross-device reduces — the type of overhead that fusion should eliminate. The model was running and the numbers were correct, but the engine was just doing more memory round-trips than it needed to.
Four pieces of work closed the gap:
- A fix to the existing
allreduce_rmsfusion pass to recognize Qwen's normalization variant — ~5% TPOT improvement at batch > 1. - Kernel-level optimizations to the qk-norm + rope path.
- Kernel fusion for the post-conv path (#37813) specific to Qwen's linear-attention architecture.
- Dual-stream execution overlapping independent compute branches.
Combined with TP=8 + expert parallelism, the production deployment reached:
- 163 tok/s at concurrency 1 (TEP=8, post-conv fusion)
- 7.33 req/s at concurrency 256, up from 6.69 req/s baseline (+10%)
This work has shipped in vLLM main.
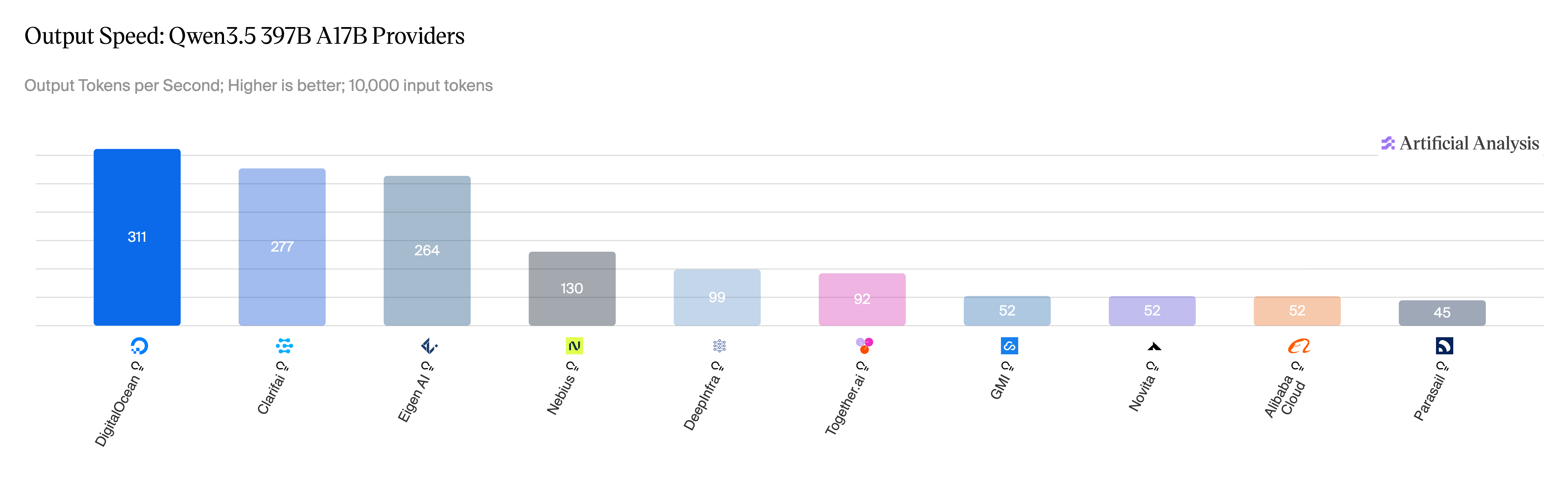
Source: Artificial Analysis, May 2026.
What this means for vLLM
Optimizations behind these results — the DSv3.2 attention-path fusions, the MiniMax EAGLE3 draft model training recipes, and the Qwen 3.5 fusions — are either already upstream in vLLM main or on their way upstream. Teams running these models on current vLLM get the same speedups.
The open-source default
Historically, the fastest inference stacks have been proprietary — built and tuned inside hyperscalers, model labs, and chip vendors for their own infrastructure. Open-source alternatives were widely usable but tended to lag on production performance.
That no longer holds at the inference layer. vLLM now tops the Artificial Analysis leaderboard for the models it supports. On these benchmarks, the fastest inference in the world is open source. The infrastructure underneath modern AI is following.
Acknowledgements
Thank you to Inferact, DigitalOcean, NVIDIA, Red Hat, and the vLLM open-source community for their contributions to this initiative.